Harshil Mathur-led Indian payments gateway platform Razorpay has been included in the Forbes Cloud 100 list for 2024. This is the company’s third consecutive appearance on the Forbes list of the top 100 cloud-computing private companies in the world. The list was released on August 6, 2024.
Razorpay remains the only Indian company featured on the list, along with global AI giants such as Open AI, Databricks, Stripe and Canva.
“Being featured on the Forbes Cloud 100 list for the third time is an incredible honour for us at Razorpay. To be the only Indian company on this prestigious list is not just a proud moment for us, but a testament to the potential and impact of India’s financial technology sector on the global stage,” said Harshil Mathur, chief executive officer and co-founder of Razorpay.
Razorpay ranks as the 70th entrant on the Forbes Cloud 100 list of companies, which highlights companies that are AI challengers and standouts in the fintech industry.
The payment gateway company has nearly 3,300 employees and has raised close to $742 million in funding from its Series A to Series F rounds, according to the list. Razorpay raised money from investors such as Lone Pine Capital, Alkeon Capital, TCV, GIC, Tiger Global, Sequoia, Capital India, Ribbit Capital, Matrix Partners, Salesforce Ventures, Y Combinator, and MasterCard.
The companies featured on the list have received funding from Bessemer Venture Partners and Salesforce Ventures, and the company data collected for the list was compiled through their help, according to the Forbes list methodology.
“The evaluation process involved four factors: estimated valuation (30 per cent), operating metrics (20 per cent), people and culture (15 per cent), and market leadership (35 per cent), which the judging panel then weighed to select, score, and rank the winners,” reported PTI, quoting a Newsvoir press release.
What’s next for Razorpay?
Razorpay estimates that the Digital P2M Payments industry in India will continue to grow and reach $4 trillion by 2030, according to the press release.
“Recognizing the ever-expanding potential for startups, freelancer, and enterprises, the company will continue to invest in building an intelligent real-time financial infrastructure, supported by next-gen AI technologies to help businesses scale and meet their ever-evolving payment and banking needs,” said the company in the statement.
Razorpay is a private startup co-founded by Harshil Mathur and Shashank Kumar. This year’s list highlights companies that have harnessed the power of AI and strategically positioned themselves for potential IPOs and market leadership.
Billionaire Elon Musk revived a lawsuit against OpenAI, giving rise to the six-year-old dispute that started with a power struggle at the San Francisco-based start-up, reported the New York Times on Monday, August 5.
The new lawsuit, filed on Monday in a Northern Californian federal court, claimed that OpenAI and two of its founders, Sam Altman and Greg Brockman, broke the company’s contract, which puts commercial interest ahead of the public good. This is similar to the claim of the original lawsuit, as per the report.
Also Read | Elon Musk to meet Yusuf Dikec in Turkey? Olympics shooter’s post goes viral
Elon Musk withdrew his original lawsuit seven weeks ago. This move came without any explanation from Musk before the judge was about to give a verdict.
Sam Altman and Brockman created OpenAI with Elon Musk in 2015 and promised to develop artificial intelligence for the benefit of humanity, as per the lawsuit. Then, allegedly, both the founders deserted the mission when the firm entered a multibillion-dollar partnership with Microsoft, according to the report.
Musk was “betrayed by Mr. Altman and his accomplices,” said the lawsuit. Open AI did not immediately respond to the New York Times’ request for comments.
Also Read | Elon Musk’s Neuralink Device Is Implanted in a Second Patient
Altman responded to Musk’s original lawsuit by saying that they intended to ask that its claims be dismissed and the company aims to cater to the public good by developing an artificial general intelligence (A.G.I.) machine capable of doing anything that the human brain is capable of, as per the report.
“The mission of OpenAI is to ensure A.G.I. benefits all of humanity, which means both building safe and beneficial A.G.I. and helping create broadly distributed benefits,” they said.
Musk separated his ties with OpenAI in 2018 after a power struggle in the company, which was created with a vision to freely share artificial intelligence technology with the public, as it was too dangerous to be controlled by a single entity like Google, according to the report. Open AI was converted into a for-profit company and it also raised $13 billion from tech giant Microsoft.
Also Read | Elon Musk calls Pavel Durov ‘Genghis Khan’ after he says he has over ‘100 kids’
The OpenAI board fired Sam Altman in November 2023, stating that the founder could no longer be trusted with the company’s mission of building artificial intelligence for the benefit of humanity. According to the report, he returned to the company after five days.
Musk sued OpenAI two months after that incident. The new case alleges that the two founders have misled Musk when they created OpenAI, according to the report.
“Elon Musk’s case against Sam Altman and OpenAI is a textbook tale of altruism over greed,” said the lawsuit. “Altman, in concert with other defendants, intentionally courted and deceived Musk, preying on Musk’s humanitarian concern about the existential dangers posed by AI,” said the lawsuit quoted in the news report.
Musk filed the new lawsuit on Monday as OpenAI allegedly violated federal racketeering laws by conspiring against Musk to defraud him, the New York Times quoted Marc Toberoff, Musk’s lawyer, as saying.
Also Read | Musk Vs Maduro: Tesla Boss Elon Musk Accepts To Fight Venezuelan President
“The previous suit lacked teeth — and I don’t believe in the tooth fairy,” said Toberoff. “This is a much more forceful lawsuit,” he said as per the report.
As per the lawsuit, OpenAI’s contract with Microsoft states that the company will not have any rights over OpenAI’s technology once the lab has achieved A.G.I., according to the report. The lawsuit also questioned whether or not the A.G.I has been achieved to determine whether the Microsoft contract should be voided or not, said the report.
OpenAI is worth more than $80 billion, according to the company’s latest funding round. Industry experts also say that OpenAI’s current technology is not A.G.I. and that the scientists do not know how to build such a system, as per the report.
Also Read | Elon Musk accepts challenge to fight Nicolas Maduro on national television
Catch all the Business News, Market News, Breaking News Events and Latest News Updates on Live Mint. Download The Mint News App to get Daily Market Updates.
MoreLess
HomeAIArtificial IntelligenceElon Musk moves court against OpenAI again; Sam Altman and Greg Brockman sued: previous case ‘lacked teeth’, says lawyer
The internet provided not only the images, but also the resources for labelling them. Once search engines had delivered pictures of what they took to be dogs, cats, chairs or whatever, these images were inspected and annotated by humans recruited through Mechanical Turk, a crowdsourcing service provided by Amazon which allows people to earn money by doing mundane tasks. The result was a database of millions of curated, verified images. It was through using parts of ImageNet for its training that, in 2012, a program called AlexNet demonstrated the remarkable potential of “deep learning”—that is to say, of neural networks with many more layers than had previously been used. This was the beginning of the AI boom, and of a labelling industry designed to provide it with training data.
The later development of large language models (LLMs) also depended on internet data, but in a different way. The classic training exercise for an LLM is not predicting what word best describes the contents of an image; it is predicting what a word cut from a piece of text is, on the basis of the other words around it.
In this sort of training there is no need for labelled and curated data; the system can blank out words, take guesses and grade its answers in a process known as “self-supervised training”. There is, though, a need for copious data. The more text the system is given to train on, the better it gets. Given that the internet offers hundreds of trillions of words of text, it became to LLMs what aeons of carbon randomly deposited in sediments have been to modern industry: something to be refined into miraculous fuel.
Common Crawl, an archive of much of the open internet including 50bn web pages, became widely used in AI research. Newer models supplemented it with data from more and more sources, such as Books3, a widely used compilation of thousands of books. But the machines’ appetites for text have grown at a rate the internet cannot match. Epoch AI, a research firm, estimates that, by 2028, the stock of high-quality textual data on the internet will all have been used. In the industry this is known as the “data wall”. How to deal with this wall is one of AI’s great looming questions, and perhaps the one most likely to slow its progress.
View Full Image
(The Economist)
One approach is to focus on data quality rather than quantity. AI labs do not simply train their models on the entire internet. They filter and sequence data to maximise how much their models learn. Naveen Rao of Databricks, an AI firm, says that this is the “main differentiator” between ai models on the market. “True information” about the world obviously matters; so does lots of “reasoning”. That makes academic textbooks, for example, especially valuable. But setting the balance between data sources remains something of a dark art. What is more, the ordering in which the system encounters different types of data matters too. Lump all the data on one topic, like maths, at the end of the training process, and your model may become specialised at maths but forget some other concepts.
These considerations can get even more complex when the data are not just on different subjects but in different forms. In part because of the lack of new textual data, leading models like OpenAI’s GPT-4o and Google’s Gemini are now let loose on image, video and audio files as well as text during their self-supervised learning. Training on video is hardest given how dense with data points video files are. Current models typically look at a subset of frames to simplify things.
Whatever models are used, ownership is increasingly recognised as an issue. The material used in training LLMs is often copyrighted and used without consent from, or payment to, the rights holders. Some AI models peep behind paywalls. Model creators claim this sort of thing falls under the “fair use” exemption in American copyright law. AI models should be allowed to read copyrighted material when they learn, just as humans can, they say. But as Benedict Evans, a technology analyst, has put it, “a difference in scale” can lead to “a difference in principle”.
Different rights holders are taking different tactics. Getty Images has sued Stability AI , an image-generation firm, for unauthorised use of its image store. The New York Times has sued Openai and Microsoft for copyright infringement of millions of articles. Other papers have struck deals to license their content. News Corp, owner of the Wall Street Journal, signed a deal worth $250m over five years. (The Economist has not taken a position on its relationship with ai firms.) Other sources of text and video are doing the same. Stack Overflow, a coding help-site, Reddit, a social-media site, and X (formerly Twitter) are now charging for access to their content for training.
The situation differs between jurisdictions. Japan and Israel have a permissive stance to promote their ai industries. The European Union has no generic “fair use” concept, so could prove stricter. Where markets are set up, different types of data will command different prices: models will need access to timely information from the real world to stay up to date.
Model capabilities can also be improved when the version produced by self-supervised learning, known as the pre-trained version, is refined through additional data in post-training. “Supervised fine-tuning”, for example, involves feeding a model question-and-answer pairs collected or handcrafted by humans. This teaches models what good answers look like. “Reinforcement-learning from human feedback” (RLHF), on the other hand, tells them if the answer satisfied the questioner (a subtly different matter).
In RLHF users give a model feedback on the quality of its outputs, which are then used to tweak the model’s parameters, or “weights”. User interactions with chatbots, such as a thumbs-up or -down, are especially useful for RLHF. This creates what techies call a “data flywheel”, in which more users lead to more data which feeds back into tuning a better model. AI startups are keenly watching what types of questions users ask their models, and then collecting data to tune their models on those topics.
Scale it up
As pre-training data on the internet dry up, post-training is more important. Labelling companies such as Scale AI and Surge AI earn hundreds of millions of dollars a year collecting post-training data. Scale recently raised $1bn on a $14bn valuation. Things have moved on from the Mechanical Turk days: the best labellers earn up to $100 an hour. But, though post-training helps produce better models and is sufficient for many commercial applications, it is ultimately incremental.
Rather than pushing the data wall back bit by bit, another solution would be to jump over it entirely. One approach is to use synthetic data, which are machine-created and therefore limitless. AlphaGo Zero, a model produced by DeepMind, a Google subsidiary, is a good example. The company’s first successful Go-playing model had been trained using data on millions of moves from amateur games. AlphaGo Zero used no pre-existing data. Instead it learned Go by playing 4.9m matches against itself over three days, noting the winning strategies. That “reinforcement learning” taught it how to respond to its opponent’s moves by simulating a large number of possible responses and choosing the one with the best chance of winning.
A similar approach could be used for LLMs writing, say, a maths proof, step-by-step. An LLM might build up an answer by first generating many first steps. A separate “helper” AI, trained on data from human experts to judge quality, would identify which was best and worth building on. Such AI-produced feedback is a form of synthetic data, and can be used to further train the first model. Eventually you might have a higher-quality answer than if the LLM answered in one go, and an improved LLM to boot. This ability to improve the quality of output by taking more time to think is like the slower, deliberative “system 2″ thinking in humans, as described in a recent talk by Andrej Karpathy, a co-founder of OpenAI. Currently, LLMs employ “system 1″ thinking, generating a response without deliberation, similar to a human’s reflexive response.
The difficulty is extending the approach to settings like health care or education. In gaming, there is a clear definition of winning and it is easier to collect data on whether a move is advantageous. Elsewhere it is trickier. Data on what is a “good” decision are typically collected from experts. But that is costly, takes time and is only a patchy solution. And how do you know if a particular expert is correct?
It is clear that access to more data—whether culled from specialist sources, generated synthetically or provided by human experts—is key to maintaining rapid progress in AI. Like oilfields, the most accessible data reserves have been depleted. The challenge now is to find new ones—or sustainable alternatives.
In 2023 Apple released the iPhone 15 Pro, powered by the a17 bionic chip, with 19bn transistors. The density of transistors has doubled 34 times over 56 years. That exponential progress, loosely referred to as Moore’s law, has been one of the engines of the computing revolution. As transistors became smaller they got cheaper (more on a chip) and faster, allowing all the hand-held supercomputing wonders of today. But the sheer number of numbers that AI programs need to crunch has been stretching Moore’s law to its limits.
View Full Image
(The Economist)
The neural networks found in almost all modern AI need to be trained in order to ascertain the right “weights” to give their billions, sometimes trillions, of internal connections. These weights are stored in the form of matrices, and training the model involves manipulating those matrices, using maths.Two matrices—sets of numbers arrayed in rows and columns—are used to generate a third such set; each number in that third set is produced by multiplying together all the numbers in a row in the first set with all those in a column of the second and then adding them all up. When the matrices are large, with thousands or tens of thousands of rows and columns, and need to be multiplied again and again as training goes on, the number of times individual numbers have to be multiplied and added together becomes huge.
The training of neural nets, though, is not the only objective that requires lightning-fast matrix multiplication. So does the production of high-quality video images that make computer games fun to play: and 25 years ago that was a far larger market. To serve it Nvidia, a chipmaker, pioneered the design of a new sort of chip, the graphics-processing unit (GPU), on which transistors were laid out and connected in a way that let them do lots of matrix multiplications at once. When applied to AI, this was not their only advantage over the central processing units (CPUs) used for most applications: they allowed larger batches of training data to be used. They also ate up a lot less energy.
Training AlexNet, the model which ushered in the age of “deep learning” in 2012, meant assigning weights to 60m internal connections. That required 4.7 x 1017floating-point operations (flop); each flop is broadly equivalent to adding or multiplying two numbers. Until then, that much computation would have been out of the question. Even in 2012, using the best CPUs would not just have required a lot more time and energy but also simplifying the design. The system that trained AlexNet did all its phenomenal FLOPping with just two GPUs.
A recent report from Georgetown University’s Centre for Emerging Technology says GPUs remain 10-100 times more cost-efficient and up to 1,000 times faster than CPUs when used for training models. Their availability was what made the deep-learning boom possible. Large language models (LLMs), though, have pushed the demand for calculation even further.
Transformers are go
In 2018 Alec Radford, a researcher at OpenAI, developed a generative pre-trained transformer, or GPT, using the “transformer” approach described by researchers at Google the year before. He and his colleagues found the model’s ability to predict the next word in a sentence could reliably be improved by adding training data or computing power. Getting better at predicting the next word in a sentence is no guarantee a model will get better at real-world tasks. But so far the trend embodied in those “scaling laws” has held up.
As a result LLMs have grown larger. Epoch AI, a research outfit, estimates that training GPT-4 in 2022 required 2 x 1025 flop, 40m times as many as were used for AlexNet a decade earlier, and cost about $100m. Gemini-Ultra, Google’s most powerful model, released in 2024, is reported to have cost twice as much; Epoch AI reckons it may have required 5 x 1025 flop. These totals are incomprehensibly big, comparable to all the stars in all the galaxies of the observable universe, or the drops of water in the Pacific Ocean.
In the past the solution to excessive needs for computation has been a modicum of patience. Wait a few years and Moore’s law will provide by putting even more, even faster transistors onto every chip. But Moore’s law has run out of steam. With individual transistors now just tens of nanometres (billions of a metre) wide, it is harder to provide regular jumps in performance. Chipmakers are still working to make transistors smaller, and are even stacking them up vertically to squeeze more of them onto chips. But the era in which performance increased steadily, while power consumption fell, is over.
As Moore’s law has slowed down and the desire to build ever-bigger models has taken off, the answer has been not faster chips but simply more chips. Insiders suggest GPT-4 was trained on 25,000 of Nvidia’s a100 GPUs, clustered together to reduce the loss of time and energy that occurs when moving data between chips.
Much of the $200bn that Alphabet, Amazon, Meta and Microsoft plan to invest in 2024 will go on AI-related stuff, up 45% from last year; much of that will be spent on such clusters. Microsoft and Openai are reportedly planning a $100bn cluster in Wisconsin called Stargate. Some in Silicon Valley talk of a $1trn cluster within the decade. Such infrastructure needs a lot of energy. In March Amazon bought a data centre next door to a nuclear power plant that can supply it with a gigawatt of power.
The investment does not all go on GPUs and the power they draw. Once a model is trained, it has to be used. Putting a query to an AI system typically requires roughly the square root of the amount of computing used to train it. But that can still be a lot of calculation. For GPT-3, which required 3 x 1023 flop to train, a typical “inference” can take 3 x 1011 flop. Chips known as FPGAs and ASICs, tailored for inference, can help make running AI models more efficient than using GPUs.
Nevertheless, it is Nvidia that has done best out of the boom. The company is now worth $2.8trn, eight times more than when Chatgpt was launched in 2022. Its dominant position does not only rest on its accumulated know-how in GPU-making and its ability to mobilise lots of capital (Jensen Huang, its boss, says Nvidia’s latest chips, called Blackwell, cost $10bn to develop). The company also benefits from owning the software framework used to program its chips, called CUDA, which is something like the industry standard. And it has a dominant position in the networking equipment used to tie the chips together.
Supersize me
Competitors claim to see some weaknesses. Rodrigo Liang of SambaNova Systems, another chip firm, says that Nvidia’s postage-stamp-size chips have several disadvantages which can be traced back to their original uses in gaming. A particularly big one is their limited capacity for moving data on and off (as an entire model will not fit on one GPU).
Cerebras, another competitor, markets a “wafer scale” processor that is 21.5cm across. Where GPUs now contain tens of thousands of separate “cores” running calculations at the same time, this behemoth has almost a million. Among the advantages the company claims is that, calculation-for-calculation, it uses only half as much energy as Nvidia’s best chip. Google has devised its own easily customised “tensor-processing unit” (TPU) which can be used for both training and inference. Its Gemini 1.5 AI model is able to ingest eight times as much data at a time as GPT-4, partly because of that bespoke silicon.
The huge and growing value of cutting-edge GPUs has been seized on for geopolitical leverage. Though the chip industry is global, a small number of significant choke-points control access to its AI-enabling heights. Nvidia’s chips are designed in America. The world’s most advanced lithography machines, which etch designs into silicon through which electrons flow, are all made by ASML, a Dutch firm worth $350bn. Only leading-edge foundries like Taiwan’s TSMC, a firm worth around $800bn, and America’s Intel have access to this tool. And for many other smaller items of equipment the pattern continues, with Japan being the other main country in the mix.
These choke-points have made it possible for the American government to enact harsh and effective controls on the export of advanced chips to China. As a result the Chinese are investing hundreds of billions of dollars to create their own chip supply chain. Most analysts believe China is still years behind in this quest, but because of big investments by companies such as Huawei, it has coped with export controls much better than America expected.
America is investing, too. TSMC, seen as a potential prize or casualty if China decided to invade Taiwan, is spending about $65bn on fabs in Arizona, with about $6.6bn in subsidies. Other countries, from India ($10bn) to Germany ($16bn) to Japan ($26bn) are increasing their own investments. The days in which acquiring AI chips has been one of AI’s biggest limiting factors may be numbered.
PWC, a professional-services firm, reckons that AI could add almost $16trn to global economic output by around 2030 (compared with 2017). McKinsey, a consulting firm, separately arrived at a similar figure, but now reckons this could rise by another 15-40% because of newer forms of AI such as large language models. Yet Africa, which has around 17% of the world’s population, looks likely to get a boost from AI in its annual GDP of just $400m by 2030, or 2.5% of the total, because it lacks digital infrastructure. As a result, instead of helping to narrow the productivity and income gap between Africa and richer countries, AI seems set to widen it.
Take Nigeria, a regional tech hub whose average download speed of wired internet is a tenth of Denmark’s. Most broadband users in Africa’s most populous country are limited to mobile internet, which is slower still. A growing number of underwater cables connect the continent with the wider world, with more to come. These include Meta’s 2Africa, the world’s longest undersea connection. But a dearth of onshore lines to carry data inland will leave much of that capacity wasted.
In some ways Africa’s weak digital infrastructure is explained by the success of its mobile revolution, whereby privately owned telcos entered newly liberalised markets, disrupting and displacing the incumbent operators. These not-so-new firms are still growing rapidly—the 15 main ones have averaged 29% revenue growth over the past five years. But their jump over landlines is coming back to bite them. In much of the rich world, the basic infrastructure of telephones—junction boxes and telephone poles or underground cable conduits—have been repurposed to provide fast fibre-optic broadband. Yet Africa is often starting from scratch.
The lack of connectivity is compounded by a shortage of the heavy-duty data centres needed to crunch the masses of data required to train large language models and run the AI-powered applications that could boost Africa’s economic growth. These days much of the content and processing needed to keep websites and programmes running is held in the cloud, which is made up of thousands of processors in physical data centres. Yet Africa has far fewer of these than any other major continent (see map).
View Full Image
(The Economist)
Without nearby data centres, bits and bytes have to make long round-trips to centres in cities such as Marseille or Amsterdam for processing, leading to lagging applications and frustrating efforts to stream high-definition films. Yet the closer data are to users, the faster they can reach them: films can zip across to viewers from one of Netflix’s African servers more quickly than you can say “Bridgerton”. The more cable landings and more local data centres there are on the continent, the more resilient its network is if undersea cables are damaged, as happened earlier this year when internet access was disrupted across much of west Africa.
All these new data centres will require more energy as they grow. AI, which involves complex calculations that need even more computing power, will further raise demand. A rack of servers needed for AI can use up to 14 times more electricity than a rack of normal servers. They also need industrial air-conditioning, which guzzles massive amounts of power and water—even more so in ever-hotter climates.
Yet Africa is so short of electricity that some 600m of its people have no power. In Nigeria, which suffers 4,600 hours of blackouts a year, data centres are forced to provide their own natural gas-powered generating plants to keep the lights on and the servers humming. Though many centres across the continent are turning to renewables, wind and solar are too erratic to do the job continuously.
Edge computing, where more data is processed on the user’s device, is promoted as a way to bring AI-powered tech to more Africans. But it relies on the presence of many smaller and less energy-efficient data centres, and on users having smartphones powerful enough to handle the calculations. Though around half of mobile phones in Africa are now smartphones, most are cheap devices that lack the processing power for edge computing.
In 18 of the 41 African countries surveyed by the International Telecommunication Union, a minimal mobile-data package costs more than 5% of average incomes, making them unaffordable for many. This may explain why almost six in ten Africans lack a mobile phone, and why it is not profitable for telcos to build phone towers in many rural areas. “Approximately 60% of our population, representing about 560m people, have access to a 4G or a 3G signal next to their doorstep, and they’ve never gone online,” says Angela Wamola of GSMA, an advocacy group for mobile operators. Every next yet-to-be-connected African is more expensive to reach than the last, and brings fewer returns, too. And new phone towers in remote areas, which typically cost $150,000 each, still need costly cables to “backhaul” data.
Part of the solution to Africa’s connectivity problem may be partnerships between mobile-phone operators and development institutions. Existing telcos know the terrain and the politics that can make laying cables a delicate task. International tech firms such as Google or Microsoft are well placed to take on more risk by laying their own cables and building data centres. Equipment-providers and other multinationals can fill skill gaps.
China’s Huawei, for example, is building 70% of Africa’s 4G networks. Startups using cheaper technologies are exploring how to help far-flung communities get connected. Africa’s connectivity mix will probably be as diverse as its people, including everything from satellites that can be put up by firms like Starlink to reach rural areas, to improved 4G networks in medium-sized cities.
Some foreign firms are investing in data centres in Kenya and Nigeria, but not enough of them. There is also some experimenting with how to power them. Kenya’s Ecocloud Data Centre, for example, will be the continent’s first to be fully run on geothermal energy, a stable source of renewable power. Since Kenya’s grid has plenty more green energy available, it is an attractive place to build more data centres.
But given how many power sources your correspondent switched between to write this article, and how many patchy internet connections interrupted her work, much still needs to be done to improve infrastructure. That is even truer if Africa’s animators, weather forecasters, quantum physicists and computer scientists are to fulfil their potential. Even small-scale farming, which provides a living for more than half the continent’s people, stands to benefit from improved access to AI.
Frustratingly, the case for improving Africa’s digital infrastructure is not new. “Gosh! I can’t believe, 15 years later, we’re still having this conversation,” says Funke Opeke, whose firm, MainOne, built Nigeria’s first privately owned submarine cable in 2010. Unless big investments are made soon, the same conversation may be taking place another 15 years on.
While this is the obvious part, beneath the surface, the bigger fight is also about controlling all streams of user data, including those from search engines and social media, which can help big tech companies such as Google, OpenAI, Microsoft, Meta, Nvidia and Elon Musk’s xAI build the world’s most powerful artificial intelligence (AI) model.
ChatGPT managed to garner more than 100 million users in just the first two months of its launch in December 2023, prompting many to dub it a search-engine killer. The reason was that ChatGPT allows us to write poems, articles, tweets, books, and even code like humans and is interactive, while search engines passively provide article links. Microsoft, which has a stake in OpenAI, even integrated ChatGPT with its own search engine, Bing. At that time, though, ChatGPT was still being tested and lacked knowledge of current events, having trained on data only till the end of 2021.
From September 2023, ChatGPT began accessing the internet, thus providing up-to-date information. But it started facing allegations of “verbatim”, “paraphrase”, and “idea” plagiarism and copyright violations from publishers around the world. Late last year, for instance, The New York Times initiated legal proceedings against Microsoft and OpenAI, alleging unauthorized “copying and using millions of its articles”. OpenAI did give publishers the option to block bots from crawling their content but separating AI bots from those originating from search engines such as Google or Microsoft’s Bing, which facilitate page indexing and visibility in search outcomes, is easier said than done.
OpenAI’s SearchGPT prototype, which is currently available for testing, will not only access the web but also provide “clear links to relevant sources”, the company said in a blog post on 26 July. This implies that more than targeting Google’s search engine, OpenAI appears to be trying to pacify and rebuild rapport with publishers it has antagonised. And this time around, OpenAI is “…also launching a way for publishers to manage how they appear in SearchGPT, so publishers have more choices”.
It clarifies that SearchGPT is about search and “separate from training OpenAI’s generative AI foundation models”. It adds that the search results will show sites even if they opt out of generative AI training. OpenAI explains that a webmaster can allow its “OAI-SearchBot to appear in search results while disallowing GPTbot to indicate that crawled content should not be used for training OpenAI’s generative AI foundation models”.
Equations are changing, but slowly
To be sure, ChatGPT’s success is already making a dent in Google’s worldwide lead, which makes most of its revenue from advertising. For instance, Google saw its smallest search market share on desktops registered in more than a decade. Microsoft’s Bing, which supported and integrated ChatGPT into its service, surpassed 10% of the market share on desktop devices, according to Statista.
Google, whose advertising search revenue was $279.3 billion in 2023, is taking a hit, with many users already preferring Generative AI (GenAI) for searching online information first. “Many companies heard the call and saw $13 billion invested in generative AI (GenAI) for broad usage, namely search engines and large language models (LLMs), in 2023,” according to Statista.
Yet, Google, according to Statista, continues to control more than 90% of the search-engine market worldwide across all devices, handling over 60% of all search queries in the US alone and generating over $206.5 billion in ad revenues from its search engine and YouTube. In India, too, the search-engine giant has a market share of over 92%, but in countries like Germany and France, though, online users are increasingly choosing “privacy- or sustainability-focused alternatives such as DuckDuckGo or Ecosia”, according to Statista. China, on its part, has Baidu, while South Korea favours Naver; even Russia’s Yandex now has the third-largest market share among search engines worldwide.
ChatGPT certainly did not topple Google, agrees Dan Faggella, founder of market research firm Emerj Artificial Intelligence Research. “But it (OpenAI) definitely was seemingly their strongest real competitor,” he adds. “I’m much more nervous for Perplexity in, say, the next three months than I am about Google,” says Fagella, for the lack of a “differentiator”.
“I think it’s a cool app. But I wonder if there’s enough of a context wrap for things like enterprise search. Google used to do enterprise search but no longer sees sense in it,” he adds. Perplexity, which has raised $100 million from the likes of Amazon founder Jeff Bezos and Nvidia, was valued at $520 million in its last funding round.
In a February interview with Mint, Srinivas argued that while Google will continue to have a “90-94% market share”, they will lose “a lot of the high-value traffic—from people who live in high-GDP countries and earning a lot of money, and those who value their time and are willing to pay for a service that helps them with the task”. He argued that over time, “the high-value traffic will slowly go elsewhere”, while low-value “navigational traffic” will remain on Google, making Google “a legacy platform that supports a lot of navigation services”.
“The bigger consideration is that the means and interfaces through which search occurs are evolving. These may become new interfaces other than the Chrome tab, where Google can very much get pushed aside, and I think the VR (virtual reality) ecosystem will be part of that as well. I don’t see Google dying tomorrow. But I think they should be shaking in their boots a little bit around what the future of search will be,” says Fagella.
Race to dominate the AI space
Fagella believes that “search is a subset of a much broader substrate monopoly game. It’s all about owning the streams of attention and activity—from personal and business users for things like their workflows, personal lives and conversations to help them (big tech companies) build the most powerful AI”. This, he explains, is why all big companies want you to have their chat assistant so that they can continue to economically dominate.
Fagella believes that all the moves indicate that the big tech companies, including Google, Meta, and OpenAI, “are ardently moving towards artificial general intelligence (AGI). “Apple’s a little quieter about it. I don’t know where Tim Cook stands. They’re always a little bit more standoffish. But suffice it to say, they’re probably in that same running as well, although seemingly not as overt about it,” he adds.
OpenAI, for instance, has multimodal GenAI models, including GPT-4o and GPT-4 Turbo, while Google’s Gemini 1.5 Flash is available for free in more than 40 languages. Meta recently released Llama 3.1 with 405 billion parameters, which is the largest open model to date, and Mistral Large 2 is a 128 billion-parameter multilingual LLM. Big tech companies are also marching ahead on the path to achieve AGI, which envisages AI systems that are smarter than humans.
OpenAI argues that because “…the upside of AGI is so great, we do not believe it is possible or desirable for society to stop its development forever; instead, society and the developers of AGI have to figure out how to get it right…We don’t expect the future to be an unqualified utopia, but we want to maximize the good and minimize the bad and for AGI to be an amplifier of humanity”.
And OpenAI does not mind spending a lot of money to pursue this goal. The ChatGPT maker could lose as much as $5 billion this year, according to an analysis by The Information. However, in a conversation this May with Stanford adjunct lecturer Ravi Belani, Sam Altman said, “Whether we burn $500 million a year, or $5 billion or $50 billion a year, I don’t care. I genuinely don’t (care) as long as we can, I think, stay on a trajectory where eventually we create way more value for society than that, and as long as we can figure out a way to pay the bills like we’re making AGI it’s going to be expensive it’s totally worth it,” he added.
In July, Google DeepMind proposed six levels of AGI “based on depth (performance) and breadth (generality) of capabilities”. While the ‘0’ level is no AGI, the other five levels of AGI performance are: Emerging, competent, expert, virtuoso and superhuman. Meta, too, says it’s long-term vision is to build AGI that is “open and built responsibly so that it can be widely available for everyone to benefit from”. Meanwhile, it plans to grow its AI infrastructure by the end of this year with two 24,000 graphics processing unit (GPU) clusters using its in-house designed Grand Teton open GPU hardware platform.
Elon Musk’s xAI company, too, has unveiled the Memphis Supercluster, underscoring the partnership between xAI, X and Nvidia, while firming up his plans to build a massive supercomputer and “create the world’s most powerful AI”. Musk aims to have this supercomputer—which will integrate 100,000 ‘Hopper’ H100 Nvidia graphics processing units (and not Nvidia’s H200 chips or its upcoming Blackwell-based B100 and B200 GPUs)—up and running by the fall of 2025.
What can spoil the party
No AI model to date can be said to have powers of reasoning and feelings as humans do. Even Google DeepMind underscores that other than the ‘Emerging’ level, the other four AGI levels are yet to be achieved. LLMs, too, remain highly advanced next-word prediction machines and still hallucinate a lot, prompting sceptics like Gary Marcus, professor emeritus of psychology and neural science at New York University, to predict that the GenAI “…bubble will begin to burst within the next 12 months”, leading to an “AI winter of sorts”.
“My strong intuition, having studied neural networks for over 30 years (they were part of his dissertation) and LLMs since 2019, is that LLMs are simply never going to work reliably, at least not in the general form that so many people last year seemed to be hoping. Perhaps the deepest problem is that LLMs literally can’t sanity-check their own work,” says Marcus.
I elaborated on these points in my 19 July newsletter, Misplaced enthusiasm over AI Appreciation Day. When will AI, GenAI provide RoI?, where Daron Acemoglu, institute professor at the Massachusetts Institute of Technology (MIT), argues that while GenAI “is a true human invention” and should be “celebrated”, “too much optimism and hype may lead to the premature use of technologies that are not yet ready for prime time”. His interview was published in a recent report, Gen AI: too much spend, too little benefit?, by Goldman Sachs.
There’s also the fear that all big AI models will eventually run out of finite data sources like Common Crawl, Wikipedia and even YouTube to train their AI models. However, a report in The New York Times said many of the “most important web sources used for training AI models have restricted the use of their data”, citing a study published by the Data Provenance Initiative, an MIT-led research group.
“Indeed, there is only so much Wikipedia to vacuum up. It takes billions of dollars to train this thing, and you’re going to suck that up pretty quickly. You’re also going to start sucking up all the videos pretty quickly, despite how quickly we can pump them in,” Fagella agrees.
He believes that the future of AI development will involve integrating sensory data from real-world interactions, such as through cameras, audio, infrared, and tactile inputs, along with robotics. This transition will enable AI models to gain a deeper understanding of the physical world, enhancing their capabilities beyond what is possible with current data.
Fagella points out that the competition for real-world data and the strategic deployment of AI in robotics and life sciences will shape the future economy, with major corporations investing heavily in AI infrastructure and data acquisition, even as data privacy and security will remain critical issues. He concludes, “The inevitable transition is to be touching the world.”
Since AI’s most popular offering, OpenAI’s ChatGPT, debuted two years back and made esoteric AI tech accessible to the masses, there has been excitement over intelligent machines taking over mundane tasks or assisting humans in complex work. Geeks declared that costs would drop and productivity skyrocket, eventually leading to ‘artificial general intelligence’, when machines would run the world.
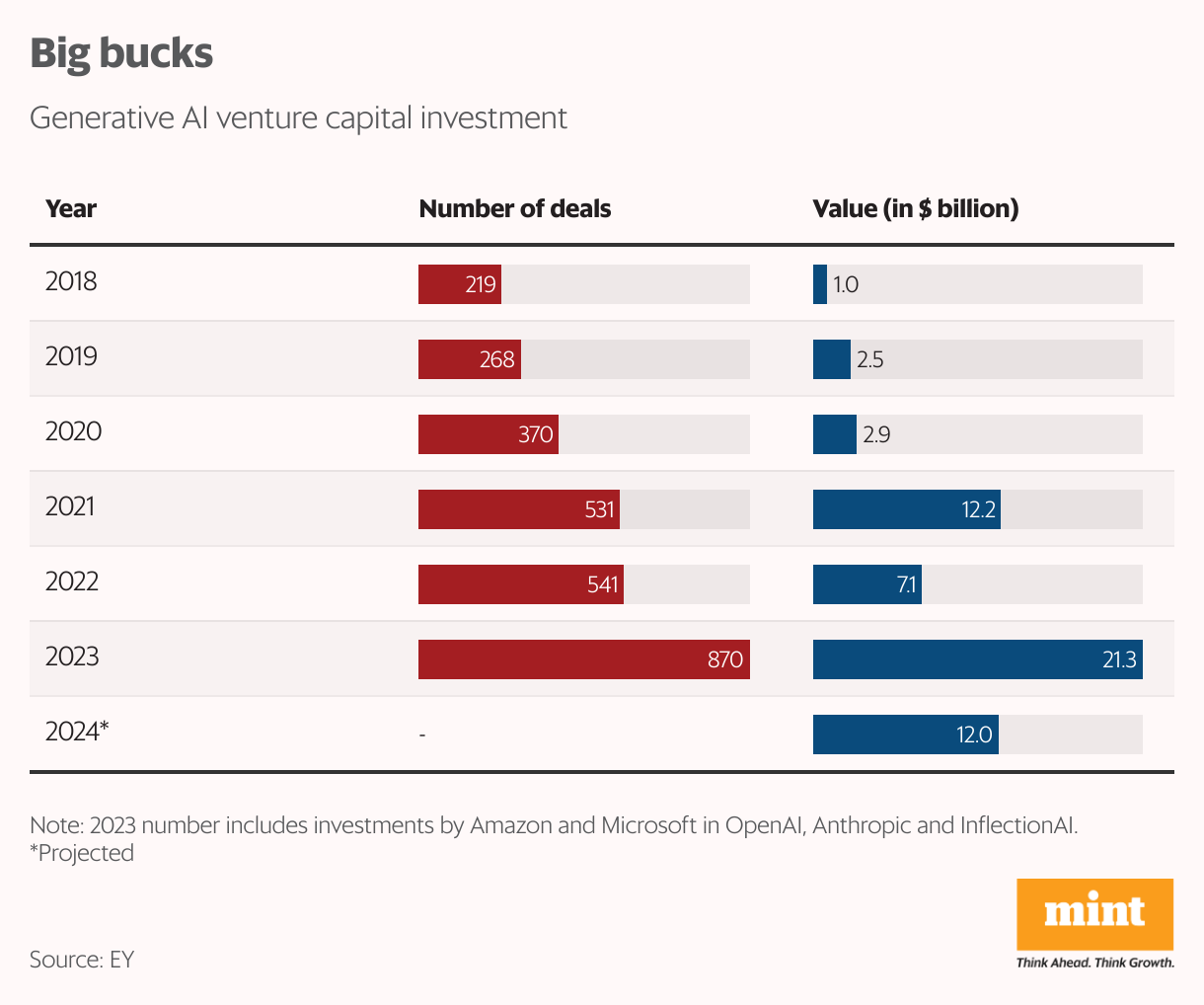
Huge sums were poured into companies focused on building AI solutions. In 2023, venture capital investments into Generative AI (a subset of AI to create text, images, video) startups totalled $21.3 billion, growing three-fold from $7.1 billion in 2022, according to consultancy EY.
But AI is a cash guzzler—Microsoft, Meta and Alphabet invested $32 billion in the first quarter of 2024 in AI development. The billions that were invested have been spent on expensive hardware, software and power-hungry data centres, totting up Big Tech valuations, but without real benefits.
Enterprises, meanwhile, have been waiting on the sidelines for the most part. With little return on investment (RoI) expected in the foreseeable future, they have been hesitant to deploy or depend entirely on AI. They also have doubts about the accuracy of AI generated results, aside from concerns over data privacy and governance.
So, while huge sums of money have been invested in AI, the rate of adoption has been slow, costs (of access) are very high, and the output is not reliable. For all the money that has been spent, AI should be able to solve complex tasks. But the only visible beneficiaries are the few big companies with a stake in AI, such as AI chipmaker Nvidia, which saw its market value jump by over $2 trillion in under two years as investors picked the stock anticipating a disruptive change. But what happened on 24 July shows that investors are running out of patience.
Inflated expectations
View Full Image
Goldman Sachs forecasts there will be expenditure of $1 trillion over the next few years to develop AI infrastructure.
Last month, Wall Street investment bank Goldman Sachs released a 31-page report on AI, questioning its benefits. Titled‘GenAI: Too much spend, too little benefit’ the report points out that AI’s impact on productivity and economic returns may have been overestimated. Jim Covello, head of global equity research, Goldman Sachs, asked, “What $1 trillion problem will AI solve?”
The venerable investment bank forecasts there will be expenditure of $1 trillion over the next few years to develop AI infrastructure but casts doubts over returns or breakthrough applications. In fact, the report warns that if significant AI applications fail to materialize in the next 12-18 months, investor enthusiasm may wane.
The flow of funds is already thinning, particularly in early-stage AI ventures. While investments in AI startups surged in 2023, the first quarter of 2024 saw just $3 billion invested globally, according to the EY report. The consultancy projects total global investment to be in the region of$12 billion in 2024, a little over half the level in 2023.
“GenAI was crowned very quickly to be the best new thing to have happened since sliced bread,” said Archana Jahagirdar, founder and managing partner, Rukam Capital, a Delhi-based early-stage investor which has backed three AI ventures—unScript.ai, Beatoven.ai and upliance.ai. “Now, there’s a realization that GenAI tech is exciting, but monetizable use cases are yet to emerge.”
Daron Acemoglu, institute professor at MIT, noted in the Goldman Sachs report that “truly transformative changes won’t happen quickly. Only a quarter of AI exposed tasks will be cost effective to automate in the next 10 years”.
Indeed, technology research and consulting firm Gartner, which popularized the concept of the new-technology hype cycle, says that Generative AI has passed the peak of inflated expectations (marked by overenthusiasm and unrealistic projections) and is entering the trough of disillusionment.
Poor RoI
“The RoI (return on investment) is not in tune with the high capex on AI. At the heart of GenAI is the ability to summarize, synthesize and create content. People are using ChatGPT, like they use Google search,” said Arjun Rao, partner, Speciale Invest, a venture capital firm.
Comparisons with another disruptive technology, the internet, are inevitable. The internet impacted every area of work, business, the economy, and society with tangible benefits—banks could expand without opening branches, or online retail could reach anyone without investing in physical stores. The internet led to the global IT services boom, as work could be sent online to tap affordable resources. This resulted in a $250 billion industry in India employing nearly five million. The internet offered cost effective and efficient alternatives. In contrast, AI will likely be replacing low-wage jobs with expensive technologies and lack of reliability, as of now.
“Unless there is RoI, companies will not invest. But we believe every business will be an AI business in future. Voice assistants are improving, and can also analyze conversations at scale. We do see adoption going up,” said Ganesh Gopalan, chief executive and co-founder, Gnani.ai. Set up by a group of former Texas Instruments engineers, Gnani.ai is a conversational AI platform backed by Samsung Ventures.
To be fair, technology disruptions are not easy and geeks tend to oversell ideas saying they will change the world. “A lot of people will lose money before they start making money,” Nishit Garg, partner, RTP Global Asia, an early-stage venture capital firm, toldMint. “This happens with every disruption we have seen, in cloud, internet and e-commerce. AI is going to raise the intelligence level of every organization. But before that happens it has to be affordable to use and error free.” RTP Global has invested in a few AI-led ventures, in areas such as market automation and drug development.
The internet, cloud, smartphones went through that hype cycle of lofty promises but eventually did improve and changed the way we work. Proponents argue that it takes a lot of money to set up infrastructure. For instance, it took billions of dollars to set up mobile networks before calls could be made.
Repeating history?
Back in 1905, Spanish-American philosopher George Santayana wrote: “Those who cannot remember the past are condemned to repeat it”. Geeks fervently believe that the next big tech idea will change the world. But history shows that many of the tech ideas that lured investors and enterprises like moths to light were either ahead of their time or just plain wrong.
For instance, after companies poured billions into solving the Y2K problem, the dotcom bubble started taking shape. Fuelled by investments in internet-based companies in the late 1990s, the value of equity markets grew exponentially during the dotcom bubble, with the Nasdaq rising from under 1,000 to more than 5,000 between 1995 and 2000. Everyone from autoparts sellers to the neighbourhood bakery were sold the idea that if they weren’t online they were doomed.
By the end of 2001, reality set in—companies were online but there were no users. TheNasdaq composite stock market index, which had risen almost 800% in just a few years, crashed from its peak by October 2002, giving up all its gains as the bubble burst.
More recent examples are the metaverse and non fungible tokens (NFTs). The metaverse was a vision that people flock to the 3D virtual web via their avatars. Analysts projected that the market would be worth over $1 trillion in a decade. NFTs started selling with eyepopping valuations. Both were swept away as AI mania took over and were clearly ahead of their time.
Still early days
For all its niggles, AI is a more fundamental technology shift than the metaverse or NFTs. But if it was having a meaningful impact, more people, at least in developed economies, would have been willing to pay to use ‘reliable’ premium services. But that is not quite the case. Open AI’s ChatGPT has around 180 million daily active users worldwide, but less than 5% (less than 9 million) pay to use it. And across companies, the use of AI varies, with digital startups using it more than traditional companies.
View Full Image
Sam Altman, chief executive officer, Open AI. (AFP)
“From a tech evolution standpoint, we are at the infrastructure buildout phase,” said Namit Chugh, principal W Health Ventures, a healthcare focused venture investor. “The middleware, services layer, applications layer will come on top of that. That’s when companies can start monetizing. The problem is AI infrastructure is very expensive to build.” W Health Ventures has invested in AI-focused startups such as Wysa, an AI assistant for people who need mental health support.
“There is a lot of FOMO—fear of missing out—ensuring that enterprises have an AI strategy. But at 60-65% accuracy AI won’t be good. This has to improve,” said RTP Global’s Garg.
“If you ignore AI you will be out of business. Ventures like Uber, Netflix, Amazon, Airbnb disrupted the market. If they don’t adapt with AI they will be dinosaurs. The problem is, a lot of people do not understand this animal,” said Arnab Basu, partner and leader, advisory, PwC India.
There is a lot of FOMO ensuring that enterprises have an AI strategy. But at 60-65% accuracy, AI won’t be good.
—Nishit Garg
The India reality
“India’s ambition is to…become one of the top three global economies in terms of GDP,” Rajnil Malik, partner and GenAI go-to-market leader, PwC India, said. AI services will play a big role in this. RoI is not evident yet, but building blocks are being put in place. Platforms like Uber were using AI from day 1, but there was no RoI for long, he added.
According to EY, 66% of India’s top 50 unicorns are already using AI. But only 15-20% of proof of concept AI projects (more like trials) by domestic enterprises have rolled out into production. However, among Global Capability Centres (GCCs), the back offices of global companies in India, the shift from PoC to roll out is around 40%. According to IT body Nasscom, there are around 1,600 GCCs in India and their numbers are growing.
About a third of the use cases in India are for intelligent assistants and chatbots. Another 25% relate to marketing automation enabled by text generation and other capabilities like test-to-images or text-to-videos. Document intelligence is emerging as a key opportunity with around one-fifth of the use cases focusing on document summarization, enterprise knowledge management and search, according to EY.
Tata Steel has partnered with an AI tech platform to use AI for green steel by reducing emissions. Indigo has introduced the AI chatbot 6Eskai to assist travellers. Ecommerce major Flipkart’s knowledge assistant Flippi uses GenAI and LLMs to offer customized recommendations. Reliance Industries and Tata Group inked a strategic pact with Nvidia in September last year to develop India-focused AI powered supercomputers, cloud (for AI use cases) and GenAI applications. The government of India has also made a provision of ₹10,000 crore to procure computing power for AI projects.
About a third of the use cases in India are for intelligent assistants and chatbots. Another 25% relate to marketing automation enabled by text generation and other capabilities.
Rao of Speciale Invest believes that in India, in sectors such as manufacturing, there may not be a blanket use of AI as it competes with relatively low labour costs. AI will be more cost effective in software development if it takes over some coding tasks, and decreases the need for additional manpower.
“There are productivity improvements,” said Mahesh Makhija, partner and technology consulting leader, EY India. “But with errors, hallucinations (when an AI model generates misleading or incorrect results), and the risk of data thefts, securitycompanies are cautious about using AI.”
But Makhija is bullish on AI’s long-term prospects. “Things will improve. The nature of work will change, like Excel sheets and PPTs decades back, collapsed business planning times from weeks to days. Further improvements will come with AI,” he said.
The human element
View Full Image
Users often find the experience of interacting with chatbots frustrating and want a human to solve their problems. (istockphoto)
An oft-cited example of AI success is Swedish fintech company Klarna. In 2023, Klarna partnered with OpenAI to develop a virtual assistant. This March, the fintech claimed its virtual agent helped shrink its query resolution time from 11 minutes to just two. The assistant does the work of 700 humans and Klarna expects to save $40 million this year.
Virtual assistants and chatbots are increasingly being used across enterprises to reduce the load (and save costs) on human contact centres and also improve what they can do (though this is mostly restricted to answering FAQs). But users often find the experience frustrating and want a human to solve their problems.
In the US, a Gartner survey of 5,728 customers, conducted in December 2023, underlined that people remain concerned about the use of AI in the customer service function. Of those surveyed, 64% said they would prefer that companies didn’t use AI in customer service. In addition, 53% of the customers surveyed stated that they would consider switching to a competitor if they found a company was going to use AI for customer service. The top concern? It will get more difficult to reach a human agent. Other concerns include AI displacing jobs and AI providing wrong answers.
“Once customers exhaust self-service options, they’re ready to reach out to a person. Many customers fear that GenAI will simply become another obstacle between them and an agent,” Keith McIntosh, senior principal, research, Gartner customer service and support practice, said in a media release earlier this month.
For AI to take off, its proponents will have to address high costs, build killer apps, and generate correct, error-free output for institutions and people. If this disruptive force is to become as ubiquitous as the internet is today, it has to show trustworthy results. Else it runs the risk of a further erosion in value as stakeholders grow impatient.
After months of rumours, Sam Altman’s startup OpenAI has finally unveiled a search engine competitor to Google called SearchGPT. The new feature is currently in ‘prototype’ stage and is only available via a waiting list, but is expected to be rolled out to all users in the future.
In a blogpost about new search feature, OpenAI wrote, “We’re testing SearchGPT, a prototype of new search features designed to combine the strength of our AI models with information from the web to give you fast and timely answers with clear and relevant sources.”
Also Read | Meta prioritizes open-source play, native Hindi support to rival OpenAI, Google
SearchGPT start page is akin to Google and we get a message reading, “what are you looking for?” After entering the search query, though, you get a direct answer much like Perplexity or Google’s disgraced AI overviews feature.
A query for music festivals in Boone, Northern California in August returns a list of all such festivals, along with a 2-3 line description that prominently mentions the source from which the information was taken. Users are also given a links option on the left-hand side of the page, where they can view all the links cited by OpenAI and open them for more detailed information. In addition, similar to ChatGPT, users can ask follow-up questions to get more information.
OpenAI, which is already being sued by major news publishers like The New York Times, said that it is committed to a thriving ecosystem of publishers and creators. The company said SearchGPT uses AI to highlight high quality content in a conversational interface while providing user the opportunity to connect with news publishers via the cited links.
ANYONE CAN spot a tipping point after it’s been crossed. Also known as critical transitions, such mathematical cliff-edges influence everything from the behaviour of financial markets and the spread of disease to the extinction of species. The financial crisis of 2007-09 is often described as one. So is the moment that covid-19 went global. The real trick, therefore, is to spot them before they happen. But that is fiendishly difficult.
Computer scientists in China now show that artificial intelligence (AI) can help. In a study published in the journal Physical Review X, the researchers accurately predicted the onset of tipping points in complicated systems with the help of machine-learning algorithms. The same technique could help solve real-world problems, they say, such as predicting floods and power outages, buying valuable time.
To simplify their calculations, the team reduced all such problems to ones taking place within a large network of interacting nodes, the individual elements or entities within a large system. In a financial system, for example, a node might represent a single company, and a node in an ecosystem could stand for a species. The team then designed two artificial neural networks to analyse such systems. The first was optimised to track the connections between different nodes; the other, how individual nodes changed over time.
To train their model, the team needed examples of critical transitions for which lots of data were available. These are hard to find in the real world, because—cue circular logic—they are so hard to predict. Instead, the researchers turned to simplified theoretical systems in which tipping points are known to occur. One was the so-called Kuramoto model of synchronised oscillators, familiar to anyone who has seen footage of out-of-sync pendulums beginning to swing together. Another was a model ecosystem used by scientists to simulate abrupt changes, such as a decline in harvested crops or the presence of pests.
When the researchers were happy that their algorithms could predict critical transitions in these systems, they applied them to the real-world problem of how tropical forests turn to savannah. This has happened many times on Earth, but the details of the transformation remain mysterious. Linked to decreased rainfall, this large-scale natural switch in vegetation type has important implications for any wildlife living in the region, as well as the humans who depend on it.
The researchers got hold of more than 20 years of satellite images of tree coverage and mean annual rainfall data from central Africa and identified the times at which three distinct regions transitioned from tropical forest to savannah. They then wanted to see if training their algorithm on data from two of these regions (with each node standing in for a small area of land) could enable it to correctly predict a transition point in the third. It could.
The team then asked the algorithm to identify the conditions that drove the shift to savannah—or, in other words, to predict an oncoming phase transition. The answer was, as expected, down to annual rainfall. But the AI was able to go further. When annual rainfall dropped from 1,800mm to 1,630mm, the results showed that average tree cover dropped by only about 5%. But if the annual precipitation decreased from 1,630mm to about 1,620mm, the algorithm identified that average tree cover suddenly fell by more than 30% further.
This would be a textbook critical transition. And by predicting it from the raw data, the researchers say they have broken new ground in this field. Previous work, whether with or without the assistance of AI, could not connect the dots so well.
Like with many AI systems, only the algorithm knows what specific features and patterns it identifies to make these predictions. Gang Yan at Tongji University in Shanghai, the paper’s lead author, says his team are now trying to discover exactly what they are. That could help improve the algorithm further, and allow better predictions of everything from infectious outbreaks to the next stockmarket crash. Just how important a moment this is, though, remains difficult to predict.
OpenAI has introduced a five-tier system to measure its progress toward developing artificial intelligence (AI) capable of surpassing human performance, reported Bloomberg. This move aims to provide clearer insight into the company’s approach to AI safety and its vision for the future. The classification system was unveiled to employees during an all-hands meeting, an OpenAI spokesperson confirmed.
Reportedly, the tiers range from the current conversational AI (Level 1) to advanced AI that can operate an entire organization (Level 5). OpenAI, widely regarded as a frontrunner in the quest for more powerful AI systems, plans to share these levels with investors and other external stakeholders.
Currently, OpenAI considers itself at the first level, but nearing the second, known as “Reasoners.” This stage refers to AI systems capable of basic problem-solving tasks comparable to a human with a doctorate, but without access to additional tools.
During the same meeting, OpenAI’s leadership showcased a research project involving its GPT-4 model, demonstrating new capabilities that exhibit human-like reasoning.
As per Bloomberg, an insider who requested anonymity, mentioned that OpenAI continually tests new functionalities internally, a standard practice in the AI industry.
OpenAI has long aimed to create artificial general intelligence (AGI), which entails developing computers that outperform humans on most tasks. Although AGI does not currently exist, CEO Sam Altman has expressed optimism that it could be achieved within this decade. The criteria for reaching AGI have been a topic of debate among AI researchers.
In November 2023, researchers at Google DeepMind proposed a five-level framework for AI, including stages such as “expert” and “superhuman,” akin to the system used in the automotive industry for self-driving cars. OpenAI’s newly introduced levels also feature five ascending stages towards AGI. The third level, “Agents,” refers to AI systems capable of performing tasks over several days on behalf of users. The fourth level involves AI that can generate new innovations, and the highest level, “Organizations,” signifies AI that can operate autonomously within an organization.
These tiers were developed by OpenAI’s executives and senior leaders and are still considered a work in progress. The company intends to collect feedback from employees, investors, and its board to refine the levels further.



")

")

")